Na úvod malý veršík: data mají cenu zlata. Takže bychom se o ně měli fakt dobře starat. Nejlépe jim ustlat na obláčku. Tím myslím nějaké Cloudové úložiště. Moje oko před časem padlo na BigQuery, což je celkem robustní datový sklad od Google, který to s daty umí opravdu hodně dobře.
Většina podobných článků začíná více či méně podrobným popisem prostředí BigQuery. Proto si dovolím tento úvod vynechat a odkážu tě na strýčka Google, jemuž BigQuery patří, aby ti nabídl nějaký popis nebo přímo referenční příručku.
Budu drze předpokládat, že máš na BigQuery normálně přístup. pokud ne, zřiď si ho. Celé kouzlo se odehrává na adrese https://console.cloud.google.com/bigquery. Tam si založíš projekt. Já ten svůj nazval „DataExtraktor“. Název projektu si dej libovolný, ale podobně přesvědčivý :-). Hned si zapni BigQuery API, abys vůbec mohl pracovat:
Jakmile to uděláš, uvidíš prostředí Exploreru. První věc bude vytvoření Datasetu, ve kterém budou vznikat tabulky s daty. Takže klikni na „Add“. Dataset vyžaduje jen doplnit název a definovat region. Já jsem si jako region zvolil „europe-west2 (London)“. Ty si klidně vyber jiný, ale pamatuj si, co sis zvolil, protože jakmile se tě v průběhu tvorby BogQuery zeptá na region u něčeho dalšího, musíš vybrat stejný.
Výborně – máme vyrobený dataset. Do něj budeme vkládat tabulky s daty. Ale abychom to nedělali ručně, musíme trochu programovat. Je jedno, jestli programování neholduješ – v tomto článku najdeš kompletní script, který jen zkopíruješ.
Start Free verze BigQuery
BigQuery pracuje do určitých limitů zdarma. A troufnu si říct, že i středně velká firma si s Free Tarifem pohodlně vystačí. Nicméně abys mohl s BigQuery pracovat, je potřeba nastavit si fakturační údaje. Google ale ujišťuje, že nic platit nebudeš ani po skončení 90 denní lhůty, během které ti daroval na útratu 300 dolarů. Takže kdo chce jít dál, vyplní platební kartu: https://console.cloud.google.com/freetrial/signup/billing/. Jen prosím od této chvíle neklikej na tlačítko „ACTIVATE“. Tím by sis zapnul automatické platby, což asi nechceš.
Servisní účet
Abys mohl s projektem pracovat, je nutné založit nějaký servisní účet a nastavit mu práva na daný projekt. Nioc složitého – na adreser https://console.cloud.google.com/projectselector2/iam-admin/serviceaccounts?supportedpurview=project si vyber svůj projekt a klikni na „Create service account“. Já třeba do názvu napsal „servis“.
V druhém kroku jsem vybral roli „Owner“, abych měl všechna práva. Třetí krok je nepovinný.
Cloud Storage
Data musíme někam uložit, a k tomu bude sloužit Cloud Storage: https://console.cloud.google.com/storage/create-bucket. Vyrobíme tedy nový Bucket. Pojmenuj si ho jak chceš, ale musíš dodržet pár pravidel. Třeba že v názvu nesmí být slovo „bucket“. Systém ti kdyžtak poradí.
V dalším kroku vybíráš opět region. Pamatuješ, jak jsem ti doporučoval zapamatovat si ho? Teď je čas si vzpomenout a dát stejný. Zbytek průvodce jen odklikej.
Tvorba Python scriptu
Využijeme toho, že se v prostředí Google Cloud Console dá napsat a spustit nějaký script. Ten se vytváří na adrese https://console.cloud.google.com/functions/. Nejspíš tam ještě žádný nemáš, tak klikni na „Create Function“.
BigQuery je chytrý. Ví, že budeš potřebovat nějaká API, takže ti je rovnou vypíše a požádá o jejich zapnutí. Udělej to. V průvodci si vyber následující:
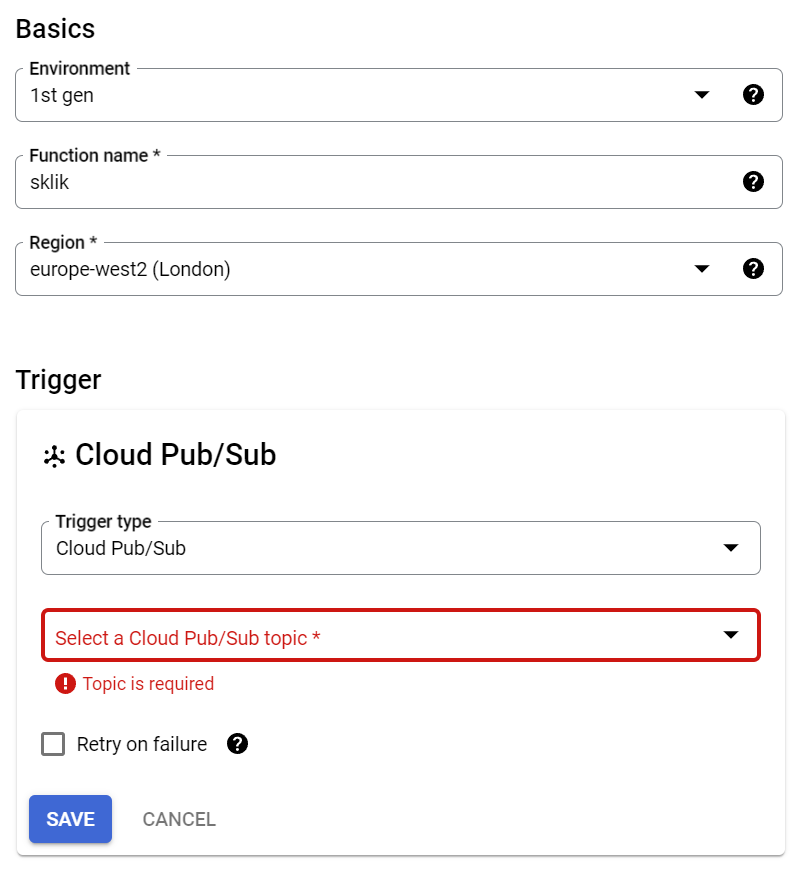
Název funkce si samozřejmě můžeš změnit podle sebe. Povinný je parametr Sub Topic. Ten ale zatím nemáme. Dá se vytvořit přímo z toho formuláře kliknutím na „Create a Topic“. Ve formuláři, který vyskočí, jen vyplníš nějaký název.
Po uložení se dostaneš dalším krokem už k vytvoření funkce pomocí python scriptu. Nejprve ale smaž soubory, které se vygenerovaly automaticky. Jde jen o ukázkový kód. Naopak vytvoř nový soubor s názvem „main.py“ a vlož následující kód:
import requests
import pandas as pd
from google.cloud import storage
from datetime import datetime, timedelta
dateTo = datetime.today()
dateFrom = dateTo - timedelta(days=30)
apiTokenSklik = "0x40451 .... @seznam.cz"
userId = 123456
def sklik_login():
response = requests.post("https://api.sklik.cz/drak/json/client.loginByToken", json=(apiTokenSklik))
res = response.json()
if res["status"] == 200:
return res["session"]
else:
return False
def api_to_gcs(endpoint, filename):
session = sklik_login()
if session != False:
data = requests.post('https://api.sklik.cz/drak/json/client.stats', json=[{"session":session, 'userId': userId},
{"dateFrom":dateFrom.strftime('%Y-%m-%d'),
"dateTo":dateTo.strftime('%Y-%m-%d'),
"granularity": "daily"}
])
json = data.json()
df = pd.DataFrame(json[endpoint])
client = storage.Client(project='DataExtraktor')
bucket = client.get_bucket('nazevbucketu')
blob = bucket.blob(filename)
blob.upload_from_string(df.to_csv(index = False),content_type = 'csv')
def main(data, context):
api_to_gcs('report', 'sklik-123456.csv')
Samozřejmě, že si budeš muset doplnit svoje údaje jako apiTokenSklik a userId. Taky si pohlídej, abys doplnil místo ‚DataExtraktor‘ správný název svého projektu a místo ‚nazevbucketu‘ taky doplň správný název.
Já si tahám statistiky klienta, ale jestli znáš API Skliku, upravíš si to tak, aby sis tahal data, jaká potřebuješ.
V záhlaví vyber jazyk „Python 3.7“ a jako Entry point napiš „main“.
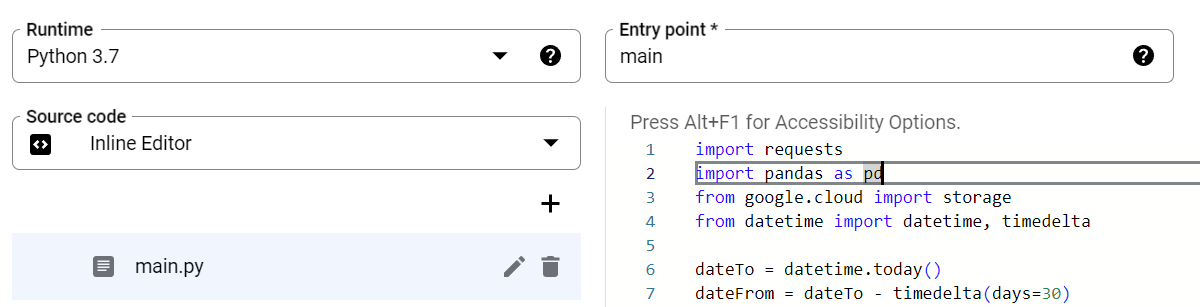
Jestli chceš mít jistotu, že ti script projde bez chyb, měl bys kliknout na „Test“. Chvíli to sice trvá, ale mělo by to doběhnout v pořádku.
Na závěr pak klikni na „Deploy“, čímž funkci zveřejníš k použití.
A přichází na řadu veliký okamžik – načtení dat do bucketu. V detailu funkce klikni na „Test the Function“:
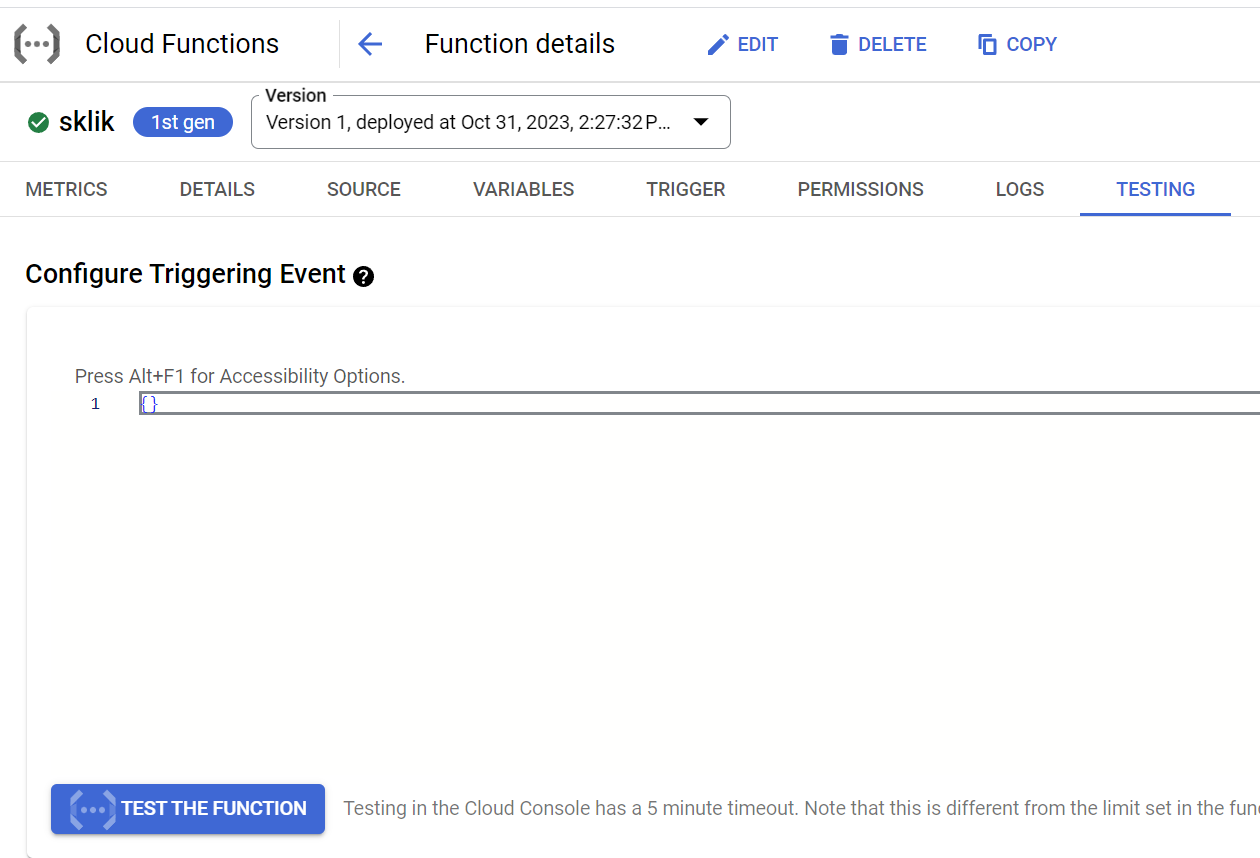
Jestlis udělal všechno správně, načetla se data z Skliku do bucketu.Na adrese https://console.cloud.google.com/storage/browser najdeš svůj bucket. Na ten klikni a uvidíš soubor sklik-123456.csv (za předpokladu, že sis ho tak pojmenoval ve scriptu.
Připojení tabulky v BigQuery
Takže data máme ve formě CSV. Teď z nich vyrobíme tabulku v BigQuery. Takže hurá na https://console.cloud.google.com/bigquery do našeho projektu. Tam vidíš svůj dataset. Klikni na ty 3 tečky vedle něj a zvol „Create table“ a vyplň následujícím způsobem:
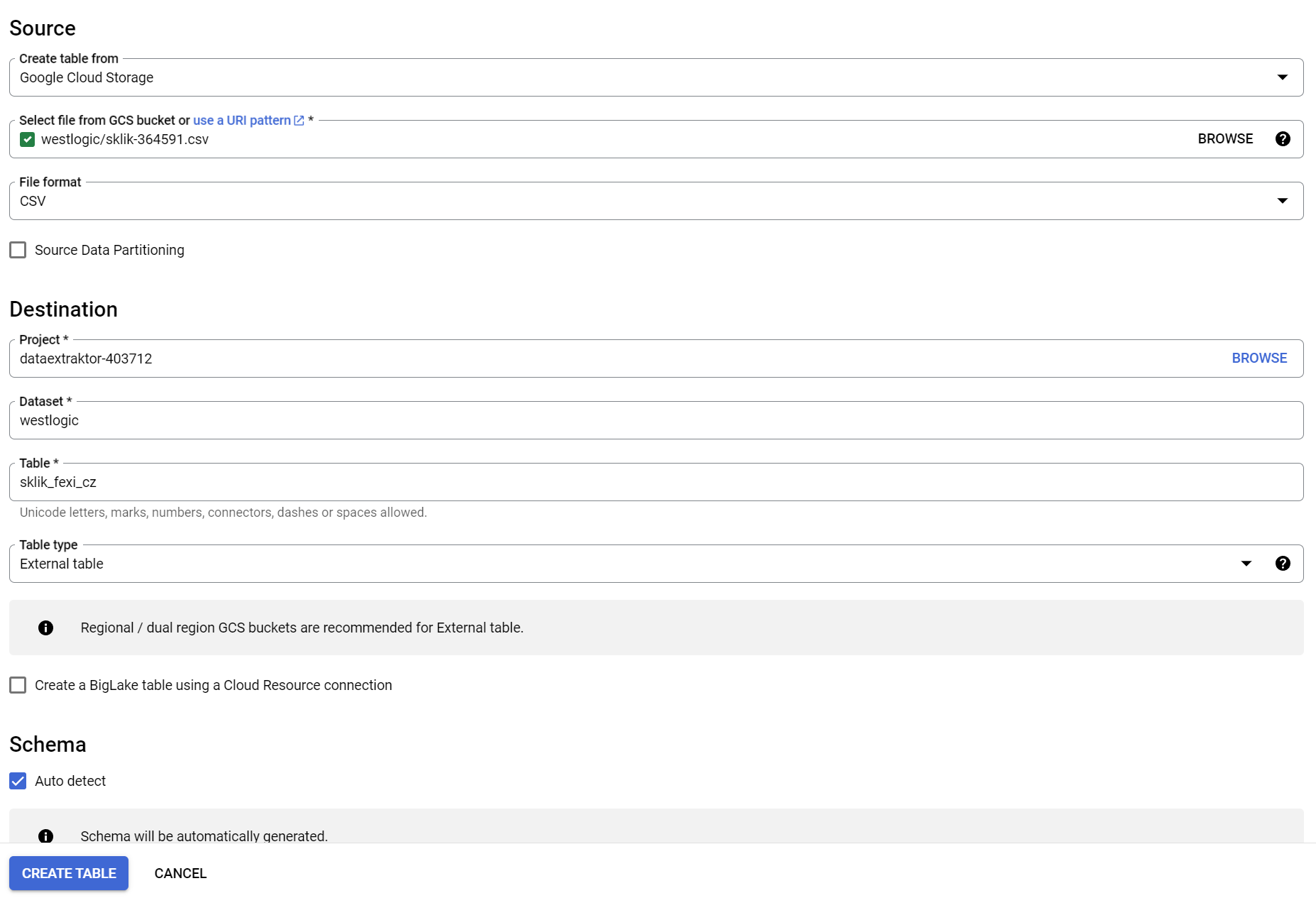
Můj bucket se jmenuje „westlogic“ a dataset taky. Ty zřejmě vyber to, co se ti nabízí při kliknutí na „Browse“. A tabulku si taky pojmenuj, abys věděl, co obsahuje za data.
Jakmile potvrdíš formulář, tabulka se vyrobí a rovnou načte data z CSV.
Automatický refresh dat
Celé je to fajn, ale klikat každé ráno ručně na refresh dat není moc pohodlné. Vyrobíme si tedy vlastní spouštěč, který to udělá za nás. A klidně každou hodinu. To se děje na adrese https://console.cloud.google.com/cloudscheduler.
Po klikutí na „Create a job“ vyplň formulář:
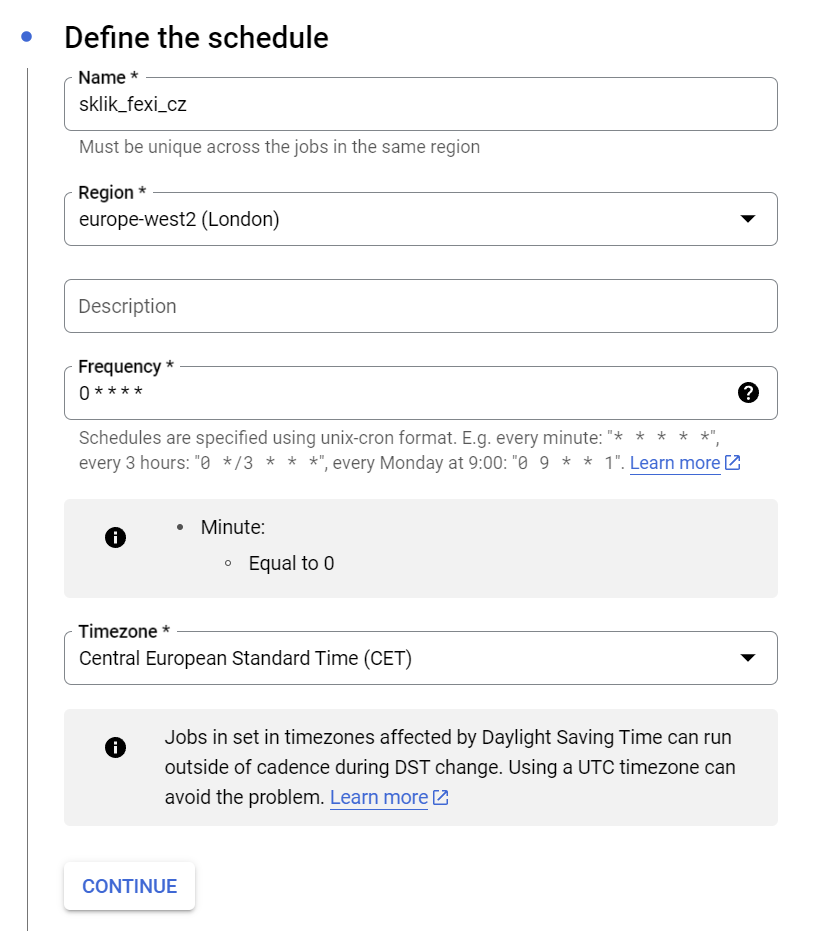
Název dej svůj a vyber pořád ten stejný region. Ta hodnota v poli „Frequency“ znamená, že se to spustí vždy v nultou vteřinu každé hodiny každého dne v roce. Timezone je také povinné, tak jsem zvolil to, kde se nachází Česko.
VB dalším kroku vybereš cíl, kam se mají data ukládat:
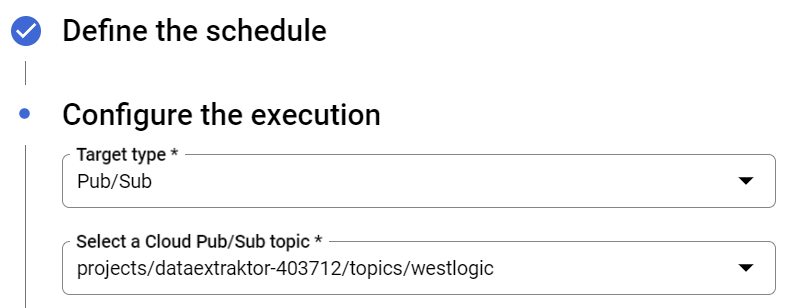
Poslední krok nech předvyplněný a potvrď. Máme vyrobený spouštěč!
Data se tedy budou obnovovat každou hodinu. Je už na tobě, jak je použiješ.